the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 10 Feb 2022
| 10 Feb 2022
Modular configuration design of a special machine tool for variable hyperbolic circular-arc-tooth-trace cylindrical gears
Haiyan Zhang
Li Hou
Shuang Liang
Yang Wu
Zhongmin Chen
In this paper, the machining principle of variable hyperbolic circular-arc-tooth-trace (VH-CATT) cylindrical gears is analysed, and a modular configuration design of this special machine tool is carried out. Based on the importance of parameter and knowledge dependence of rough set theory, the degree of influence of the index hidden in the data on the decision-making results is mined, and an algorithm for calculating the objective weight of the index is given. The comprehensive weight of the index is then obtained, combining the analytic hierarchy process. After obtaining the results of the index's comprehensive weight and module attribute classification, a module retrieval strategy is formulated using the fuzzy similarity priority ratio algorithm. Based on the modular division of this special gear-making machine tool, the modular configuration sequence of the machine tool using the depth-first search algorithm is determined. According to the module retrieval strategy and configuration sequence, a traversal of module instances is carried out, and a variety of modular configuration schemes of the machine tool is obtained, which provides a practical and efficient method for the rapid design of a special machine tool for VH-CATT cylindrical gears.
- Article
(360 KB) - Full-text XML
- BibTeX
- EndNote





A variable hyperbolic circular-arc-tooth-trace (VH-CATT) cylindrical gear is a new type of transmission form. Its tooth profile consists of a spatial arc in the tooth's width direction, the middle section of the tooth profile is involute and the other sections comprise envelopes of the hyperbolic family that uniformly change. The new gear transmission has the advantages of good meshing performance, large coincidence coefficient, large bearing capacity, high transmission efficiency, no additional axial force, long service life, high stability and low noise.
Because of the particularities of its gear tooth geometry, its specific processing equipment needs to be improved. The manufacture of VH-CATT cylindrical gears is inefficient, time-consuming and expensive, so their large-scale applications in the industrial field are limited. Therefore, it is urgent to research and develop the special machine tool for VH-CATT cylindrical gears. Product modularization and modular configuration are the relevant key technologies and enabling means to realize rapid product customization (Liu, 2008; Luo, 2011). Product configuration is based on modularization and standardization, and personalized products meeting customer needs are realized through different selections and reasonable matchings of modules (Luo, 2011). Therefore, the research on the key technologies of the modular configuration design of a special machine tool for VH-CATT cylindrical gears has important theoretical value for enhancing the market competitiveness of new gears, shortening the product design and development cycle, reducing the product production costs and improving the production capacity of enterprises.
Scholars have conducted extensive research on all aspects of product configuration. Fujita (2002) studied a method of configuring products with modules, where the number of instance libraries was determined jointly by the characteristic parameters of the modules and number of combinations, so the configuration problem was transformed into a problem consisting of the characteristic parameters and number of combinations. Lou et al. (2006) proposed that product configuration design could be considered a product design process to meet customers' personalized needs through reasonable matchings and combinations based on a predefined product configuration model of each component set and mutual constrained relationship. Xu et al. (2011) proposed a modular configuration design method for a numerical control machine tool with multi-domain interoperability and developed a modular configuration design prototype system. Mourtzis et al. (2015) used simulated annealing and tabu search algorithms to model and solve product configuration problems. Badurdeen et al. (2018) proposed a product configuration design optimization method based on multiple life cycles. Yuan (2020) built a personalized product configuration network based on data mining technology, constructing a multi-objective product configuration optimization model aimed at customer satisfaction and product sustainability. He et al. (2021) proposed a product family design and product configuration method based on system data mining, and divided the module instances into optional modules, general modules and special modules, then a product platform was established based on the general modules. In general, the process of configuration design is essentially a process of concreting and instancing the modules in the configuration model, which is a process of knowledge reasoning (Wang, 2016). The module retrieval algorithm and the determination of the module configuration sequence are the key technical problems in the process of configuration design.
This paper takes a special machine tool for VH-CATT cylindrical gears as the research object. On the premise of machine tool modularization, the module configuration sequence for the machine tool is determined based on the depth-first search algorithm. The modules are retrieved based on rough set theory and the fuzzy similarity priority ratio algorithm, instanced and traversed according to the configuration sequence and then a machine tool module configuration scheme is obtained. The flow chart of the modular configuration scheme is shown in Fig. 1.
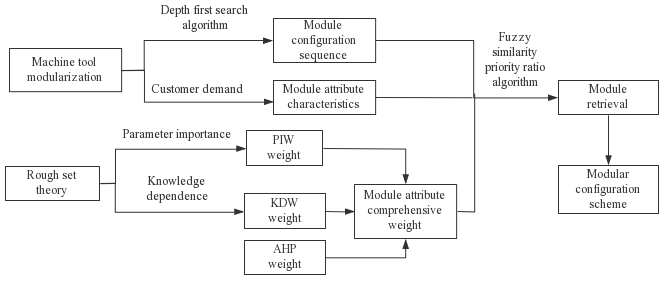
Figure 1Flow chart of the modular configuration scheme for a special machine tool for VH-CATT cylindrical gears.
As a data analysis and processing theory, rough set theory was founded by Polish scientist Pawlak Zdzistaw in 1982 (Pawlak, 1982); it is a mathematical tool that deals with fuzzy and uncertain systems. All the information it needs is provided by the given data without additional information or parameters (Das et al., 2021). From the perspective of rough set theory, this paper proposes an algorithm to calculate the objective weight of each indicator according to parameter importance and knowledge dependence, which is then combined with an analytic hierarchy process (AHP) to obtain a more ideal comprehensive weight, which can greatly improve the accuracy of the weight calculation (Sun, 2013; Wu, 2007) and improve the universality of this method.
2.1 Objective weight calculation of the index based on parameter importance
The main idea of calculating the objective weight of index based on a parameter of importance weight (PIW) is as follows. According to the upper and lower approximations of rough set theory, the importance of each system parameter is calculated, so that the degree of influence of index parameters hidden in data on decision-making and judgement results can be analysed (Zhu, 2018). Then the index weight can be calculated according to the importance of each parameter (Tan, 2012).
Assuming that the knowledge base is , R∈IND(K) represents one or more system parameters of system characteristics (Hadrani et al., 2020). The subset X in discourse domain U is X(X∈U), the partition of discourse domain U with respect to system parameter R is , the lower approximation of subset X with respect to knowledge R is , the upper approximation is , the boundary domain is bnR(X), the upper approximation contains all elements that may belong to X and the lower approximation contains all elements that can be accurately classified to X using knowledge R. The upper and lower approximations and boundary fields of X with respect to knowledge R are as follows:
For any set X∈U, the amount of information provided by X relative to the system parameter R is called the importance of X. Then the calculation equations of the importance sigR(X) of set X with respect to the system parameter R and the importance sigR(π(U)) of partition with respect to the parameter R are as follows:
In the above equations, , if sigR(X)=1, and set X can fully represent the system parameter R; if sigR(X)=0, set X cannot represent the system parameter R. With an increase of importance of X relative to R, the degree of using set X to represent system parameter R will also increase. |⋅| represents the cardinal number of the set, that is, the number of elements in the set.
Next we calculate the weighted value of each index according to the parameter importance following Eq. (5):
The algorithm flow chart of calculating the objective weight according to parameter importance is shown in Fig. 2.

Figure 2Flow chart of the objective weight calculation algorithm according to parameter importance.
2.2 Objective weight calculation of the index based on knowledge dependence
The main idea of calculating index weights based on knowledge dependence weight (KDW) is to research the knowledge dependence theory according to rough set theory (Bai et al., 2021; Naouali et al., 2020). First, calculate the knowledge dependence of each index, and then calculate the weight of index parameters. Assuming that knowledge base , ∀P, and Q∈IND(K), the equation of the knowledge dependence γP(Q) of knowledge Q that depends on P is as follows:
which is abbreviated as P⇒kQ, where
is the P positive field of knowledge Q, which is the set of all information classified by that can be accurately divided into Q equivalence classes.
In the above equation, . If γP(Q)=1, it means that P contains all the information of Q, and the dependence of Q on P is complete. If γP(Q)=0, P does not contain any Q information at all, and Q and P are completely independent; if, however , P contains only part of the information of Q, and it can also be said that Q depends on P to the degree of k.
Next we calculate the weighted value of each index according to the knowledge dependence following Eq. (7):
The algorithm flow chart of calculating the objective weight according to knowledge dependence is shown in Fig. 3.
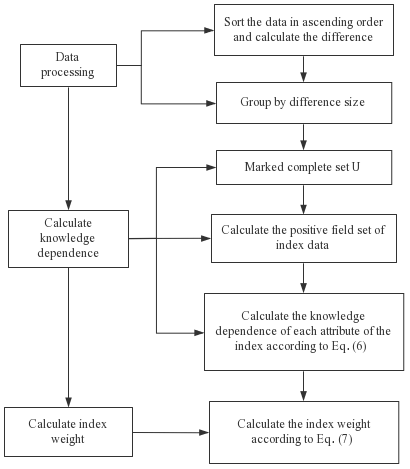
Figure 3Flow chart of the objective weight calculation algorithm according to knowledge dependence.
2.3 Calculation of the comprehensive weight of the index
The comprehensive weight is obtained by combining the objective weight determined by rough set theory with the index weight determined by AHP (Foteinopoulos et al., 2019), which is combined with the prior knowledge of the evaluator, thus realizing the unification of subjective and objective. The AHP method combines quantitative methods with qualitative methods, which decomposes the original complex problems, systematizes people's thinking process and is more convenient for people to accept and apply.
We record ωi as the comprehensive weight of the i index, given as
where ω3i is the index weight determined by the AHP (Rajput et al., 2021), and is an empirical factor , where the smaller is, the more attention it pays to the objective weight.
In the process of product configuration design, module retrieval and matching are key points (Song, 2014), where expression of the module attributes is the primary premise of module retrieval. Attributes are used to describe the parameters in the module that can be expressed in words or values (such as structural form or size or specification) (Zhang, 2012). According to the weighted value of each attribute of the machine tool module, various attribute factors are comprehensively considered, to achieve the purpose of retrieving the nearest module instance.
During module retrieval, we set the target module as Mt. The module library of such module has n modules, which are set as . Then we calculate the fuzzy priority similarity ratio between the module attribute of the target module and the corresponding attribute of the optional module in the module library.
The fuzzy similarity priority ratio is a method for comparing the samples with a fixed sample to determine which one is more similar to the fixed sample, so as to select the one with the greatest similarity to the fixed sample (Wei et al., 2017). Each module of the machine tool has multiple unique attributes.
There is a certain attribute set of module to be compared, and compare any with the fixed sample xk, i, . Here rij is assumed to indicate the degree of superiority of xi compared to xj or xj compared to xi when xi and xj are compared with fixed samples xk. If , xi is prior to xj; if , xj is prior to xi. The priority ratio meets the following conditions:
The above conditions show that when making comparisons, there is no priority, and xi and xj are equivalent, which is denoted as rii=1. When comparing, each has its own advantages and combines the priorities of the two; that is . When xi has obvious advantages over xj, but xj has no advantages over xi, rij=1 and rji=0; when xi and xj are compared regardless of their advantages and disadvantages, .
Matrix is a fuzzy similarity priority ratio matrix, where rij is defined as the Hamming distance (Taheri et al., 2020):
where and .
After the matrix is established, we take the lowest definite bound of the elements in the non-diagonal of each row and then get the highest priority object according to the row where the maximum value in the lowest definite bound is located. Then, we remove the column and row of this object to form a new matrix. This operation is repeated for the new matrix to obtain the good and bad sequence of samples in X. Finally, we number each sequence with a natural number.
If there are m attributes that need to be compared, each attribute needs to be processed separately. The method of determining the index weight based on rough set theory and AHP in the previous section is applied to give a weight to the importance of each attribute, and the weighted average method is used for fuzzy comprehensive evaluation. The equations are as follows:
where S represents the total similar sequence number, where the smaller the S value of the comparison sample, the more similar it is to the fixed sample, which is the target module.
The depth-first search algorithm is similar to the pre-order traversal of the tree (Fu et al., 2019; Cao et al., 2020), which searches the depth direction as much as possible (Nimmanterdwong, 2018). The basic idea is to visit the starting point V firstly and mark it as visited, then start from V and search each adjacent point W of V in turn. If W has not been accessed, start from W and continue to traverse the other nodes in the way of a depth-first search until all vertices connected to the source node V in the graph are accessed. At this time, if there are any points that have not been accessed, we need to select another one as the new source node and repeat the above access process until all the nodes in the figure are accessed.
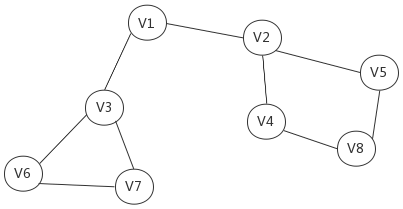
For example, Fig. 4 shows an undirected graph. The process of traversing the graph using the depth-first search algorithm is as follows:
-
First, find a vertex randomly that has not been traversed. For example, starting from V1, since V1 has been visited first, it is necessary to mark the state of V1 as visited.
-
Then traverse the adjacency point of V1. For example, access V2 and mark it, and then access the adjacency point of V2, for example, V4 (mark), then V8 and then V5.
-
When continuing to traverse the adjacency points of V5, all adjacency points have been accessed according to the previous marks. At this time, go back from V5 to V8 to see if there are any unreachable adjacency points of V8. If not, continue to go back to V4, V2 and V1.
-
By looking at V1, find a vertex V3 that has not been accessed, continue to traverse and then access V3's adjacency points, V6, then V7.
-
Since there are no unreachable adjacency points of V7, go back to V6, then continue to go back to V3 and finally reach V1. Continue until there are no unreachable adjacency points.
-
The last step is to determine whether all vertices are accessed. If there are still unreachable vertices, take the unreachable vertex as the first vertex and continue to traverse according to the above steps.
According to the above steps, the traversal sequence of the vertices obtained by the depth-first search algorithm in Fig. 4 is as follows:
When configuring the machine tool, there is a sequence for every module. The depth-first search algorithm is used to traverse and solve, so as to determine the modular configuration sequence of the machine tool.
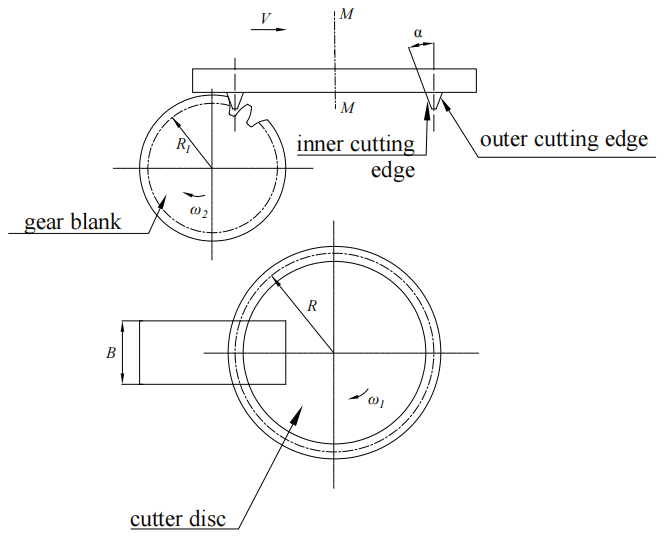
A VH-CATT cylindrical gear is machined by double edges cutters with rotating cutter disc (Zhao, 2016), and its processing principle is shown in Fig. 5. When using a double edges cutter, the rotary cutter disc for processing VH-CATT cylindrical gears is installed on the machine tool's main shaft and rotates at an angular speed of ω1 around its own axis M–M. The cutters are fixed on the cutter disc and rotate synchronously with it. The angles between the inner or outer edge of the cutter and cutter axis or axis of the rotary cutter disc are both α (i.e. pressure angle). The cutter edge rotates with the cutter disc to form two conical surfaces, where the outer cutting edge is a positive cone (machining a concave surface), and the inner cutting edge is an inverted cone (machining a convex surface). During cutting, the gear blank rotates around its own axis as it moves back and forth along the horizontal direction, forming a close generative movement with the cutters. During the machining process, the cutters cut out the concave convex tooth surface of the gear tooth at the same time. After machining a pair of tooth surfaces, it is necessary to pitch then start machining the next pair of tooth surfaces until the machining of the whole gear is completed.
During the machining process, the cutter disc rotates around the main shaft, and the gear blank rotates around its own axis at an angular speed of ω2. At the same time, the gear blank moves horizontally close to the cutter disc at a speed of V. The relationship between the two is
where R1 is the gear pitching circle radius, R is the cutter disc's radius and B is the width of the gear blank.
To realize the rapid customization of the special machine tool for VH-CATT cylindrical gears, the machine tool is divided into modules, where each type of module has different types and models from which to choose, as shown in Table 1.
Table 1Modules of the special machine tool for VH-CATT cylindrical gears.

Considering the machining principle of VH-CATT cylindrical gears and the assembly relationship between the modules, the final undirected graph is shown in Fig. 6.

Figure 6Modular configuration sequence of the special machine tool for VH-CATT cylindrical gears.
The configuration sequence solved by the depth-first search algorithm is
According to the configuration sequence, we select the no. 1 body module as the first module for retrieval and retrieve the fully matched module or similar module of this module. The module attributes of the module and other related modules are taken as the attributes of related modules. After the module is retrieved, the associated attributes can be taken as its qualitative attributes. Then, instance search traversal is carried out according to the configuration sequence until all module attributes are instanced. After the final instance, the scheme meeting the requirements can be obtained.
Let us take the no. 3 cutter disc module, i.e. the 9th retrieval module, as an example to illustrate the module retrieval process. The corresponding attributes of the cutter disc module are shown in Fig. 7.
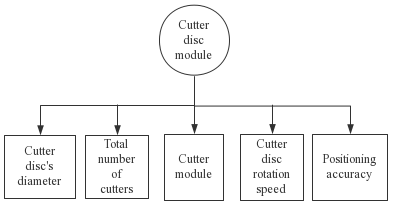
The attribute characteristic values of the cutter disc's target module are obtained through the customer demand analysis, as shown in Table 2.

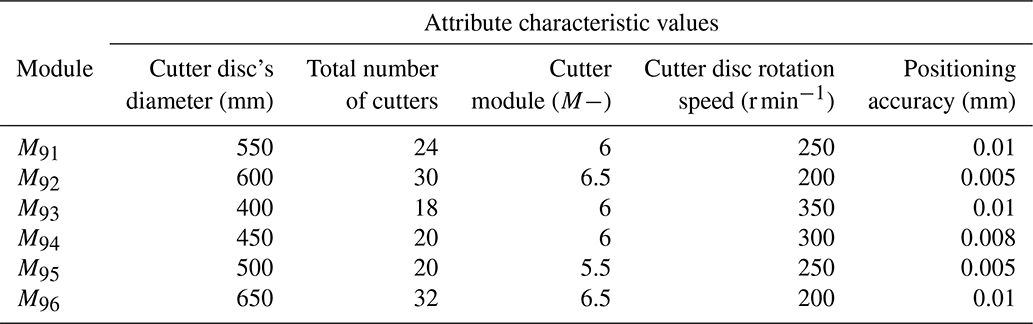
The attribute characteristic values of the cutter disc module are obtained from the cutter disc module library of the machine tool, as shown in Table 3, where M9i represents the ith module in the 9th type module, and M9t is the target module of the 9th type module.
Table 3Attribute characteristic values of the cutter disc module.
Next we calculate the parameter importance of each attribute according to Eq. (4), as shown in Table 4.
Table 4Parameter importance of the cutter disc module attributes.

Then we calculate the weighted value of each attribute according to Eq. (5), as shown in Table 5.
Table 5PIW weighted values of the cutter disc module attributes.

Based on Eqs. (6) and (7), we calculate the dependence and weight of each attribute of the cutter disc module according to the knowledge dependence. Finally, we combine the AHP with Eq. (8) and assign greater weight to the objective taking to obtain the comprehensive weight of each attribute, as shown in Table 6.
Table 6Comprehensive weighted values of the cutter disc module attributes.


We used a line chart to compare the weighted values calculated by the above four methods, the results of which are shown in Fig. 8. According to the parameter importance and knowledge dependence, the objective weight of the index is obtained, which is combined with the AHP algorithm to obtain its comprehensive weight. This approach improves upon the deficiencies of each single assignment method to a certain extent, improves the rationality of the weight calculation and makes the final decision more accurate.
On the basis of Eqs. (9) and (10), the fuzzy similarity priority ratio matrices R1, R2, R3, R4 and R5, respectively describing the cutter disc's diameter, total number of cutters, cutter module, cutter disc rotation speed and positioning accuracy, are calculated according to the fuzzy similarity priority ratio algorithm, as follows:
According to the method described above, the order of the M95 module corresponding to the attribute “cutter disc's diameter” should be 1. By then deleting its row and column, we can calculate the next order. We then sort the attributes of the module with natural numbers and finally get the priority of the attributes of the cutter disc module, as shown in Table 7.

According to the comprehensive weighted values of the attributes of the cutter disc module obtained in Table 6, the data obtained in Table 7 are weighted and summed according to Eq. (11) to obtain the corresponding similarity of each module, where the smaller the value, the higher the similarity. As shown in Table 8, it can be seen that the ideal module is the one closest to the target module.

It can be seen that the module M94 and the module M95 are similar to the target module. We search and match each module of the machine tool in turn, and the search results are shown in Table 9.

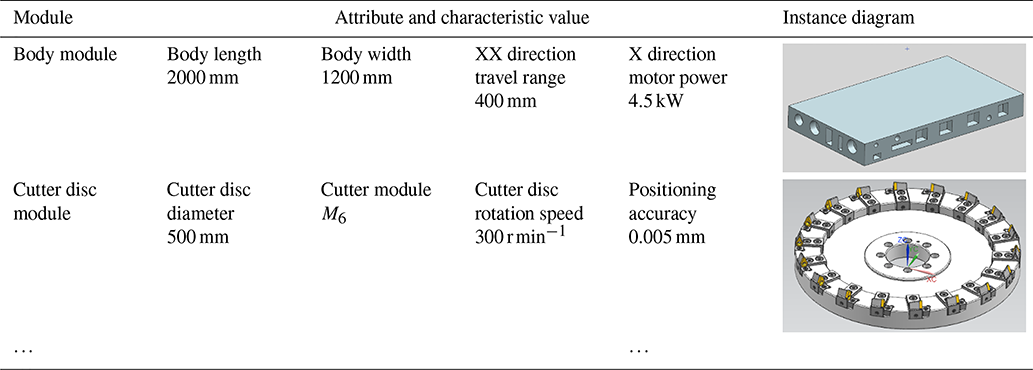
The module combination obtained after the final retrieval and matching is taken as the product scheme, and six configuration schemes of the special machine tool for VH-CATT cylindrical gears are obtained through the module combination . After module selection and variant design, the final machine tool configuration scheme is obtained, as shown in Table 10.
Table 10Configuration result of the main modules of the special machine tool for VH-CATT cylindrical gears.
In this paper, research on module retrieval and configuration of a special machine tool for VH-CATT cylindrical gears is carried out. This approach provides a foundation for the rapid design of machine tool. It is also suitable for other complex electromechanical products. The conclusions of this study are summarized as follows:
-
According to the parameter importance and knowledge dependence of rough set theory, this paper proposes an algorithm to calculate the objective weight of the index, and its comprehensive weight is obtained by combining the AHP method. Our approach complements the traditional subjective weight calculation method, which can not only greatly improve the accuracy and rationality of the calculated weighted value, but also improve the universality of the method.
-
Based on the processing principle of the special machine tool for VH-CATT cylindrical gears, the divided machine tool modules are searched and solved based on the depth-first search algorithm to determine their configuration sequences.
-
Applying the fuzzy priority similarity ratio algorithm, each module of the machine tool is retrieved and matched according to the configuration sequence, and various attribute factors are comprehensively considered according to the weight value of each attribute of the machine tool module. This allowed us to achieve the purpose of retrieving the most similar module examples and finally obtain a variety of machine tool module configuration schemes.
All the data used in this article can be obtained upon request from the corresponding author.
HZ put forward the creativity of the article and wrote the paper, LH and SL gave suggestions for improvement, and YW and ZC assisted and revised the paper. All authors have read and agreed to the published version of the paper.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was done with support from the National Natural Science Foundation of China (grant no. 51875370).
This research has been supported by the National Natural Science Foundation of China (grant no. 51875370).
This paper was edited by Xuping Zhang and reviewed by three anonymous referees.
Badurdeen, F., Aydin, R., and Brown, A.: A multiple lifecycle-based approach to sustainable product configuration design, J. Clean. Prod., 200, 756–769, https://doi.org/10.1016/j.jclepro.2018.07.317, 2018.
Bai, Y., Xie, J. J., Wang, D. Q., Zhang, W. J., and Li, C.: A manufacturing quality prediction model based on AdaBoost-LSTM with rough knowledge, Comput. Ind. Eng., 155, 107227, https://doi.org/10.1016/j.cie.2021.107227, 2021.
Cao, Z. Y.: Transit network optimization based on depth-first-search and meta-heuristics algorithm, MS thesis, Southwest Jiaotong University, China, 65 pp., https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CMFD&dbname=CMFD202102&filename=1021575076.nh&uniplatform=NZKPT&v=UxGSJ3CqGNBoFsD76WQ8ZsHK7cB06S47OAMqzx9A10WvugUNdpNaXom6JnmXppuQ (last access: 8 February 2022), 2020.
Das, M., Mohanty, D., and Parida, K. C.: On the neutrosophic soft set with rough set theory, Soft Comput., 25, 13365–13376, https://doi.org/10.1007/s00500-021-06089-2, 2021.
Foteinopoulos, P., Papacharalampopoulos, A., and Stavropoulos, P.: Block-based analytical hierarchy process applied for the evaluation of construction sector additive manufacturing, Proc. CIRP, 81, 950–955, 2019.
Fu, J. H., Tian, M. X., and Gao, Y. B.: Identification and analysis of hybrid compensation network topology based on depth-first search algorithm, Engineering Journal of Wuhan University (Engineering Edition), 52, 344–350, https://doi.org/10.14188/j.1671-8844.2019-04-010, 2019.
Fujita, K.: Product variety optimization under modular architecture, Comput. Aided Design, 34, 953–965, https://doi.org/10.1016/S0010-4485(01)00149-X, 2002.
Hadrani, A., Guennoun, K., Saadane, R., and Wahbi, M.: Fuzzy rough sets: Survey and proposal of an enhanced knowledge representation model based on automatic noisy sample detection, Cogn. Syst. Res., 64, 37–56, https://doi.org/10.1016/j.cogsys.2020.05.001, 2020.
He, C., Li, Z. K., Wang, S., and Liu, D. Z.: A systematic data-mining-based methodology for product family design and product configuration, Adv. Eng. Inform., 48, 101302, https://doi.org/10.1016/j.aei.2021.101302, 2021.
Liu, Q.: Research on techniques and system for mass customization oriented product configuration, PhD thesis, Hefei University of Technology, China, 154 pp., https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CDFD&dbname=CDFD9908&filename=2008143776.nh&uniplatform=NZKPT&v=EY1mOsAef9xDZXv0tBqZ47y2k8aTDiqCwApbBjoCbx0xnw88Q5uOPa9awTt-PMxf (last access: 8 February 2022), 2008.
Lou, J. R., Yi, G. D., Zhang, S. Y., and Tan, J. R.: Research on product extensible configuration andevolution design based on knowledge, Journal of Zhejiang University (Engineering Science), 40, 466–470, https://doi.org/10.3785/j.issn.1008-973X.2007.03.020, 2006.
Luo, Y.: Research on key techniques of product family configuration based on cases for mass customization, PhD thesis, Chongqing University, China, 114 pp., https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CDFD&dbname=CDFD1214&filename=1012008828.nh&uniplatform=NZKPT&v=H97LlvbBwJlZy7IhhoItpZuwcjHnR7SdRuOkZLRLM2oaS3ykEZH4f3YVNwuRKNiT (last access: 8 February 2022), 2011.
Mourtzis, D. and Doukas, M.: On the configuration of supply chains for assemble-to-order products: Case studies from the automotive and the CNC machine building sectors, Robot. Cim.-Int. Manuf., 36, 13–24, https://doi.org/10.1016/j.rcim.2015.02.009, 2015.
Naouali, S., Salem, S. B., and Chtourou, Z.: Uncertainty mode selection in categorical clustering using the rough set theory, Expert Syst. Appl., 158, 113555, https://doi.org/10.1016/j.eswa.2020.113555, 2020.
Nimmanterdwong, P., Chalermsinsuwan, B., and Piumsomboon, P.: Development of an emergy computation algorithm for complex systems using depth first search and track summing methods, J. Clean. Prod., 193, 625–641, https://doi.org/10.1016/j.jclepro.2018.05.088, 2018.
Pawlak, Z.: Rough set, Int. J. Comput. Inf. Sci., 11, 341–356, https://doi.org/10.1007/BF01001956, 1982.
Rajput, V., Sahu, N. K., and Agrawal, A.: Optimization of waste kota stone dust filled epoxy composite by analytical hierarchy process (AHP) approach, Mater. Today-Proc., https://doi.org/10.1016/j.matpr.2021.09.168, online first, 2021.
Song, J. Y.: Research on configuration design of product service system for CNC machine tools, MS thesis, Northeastern University, China, 101 pp., https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CMFD&dbname=CMFD201501&filename=1015557942.nh&uniplatform=NZKPT&v=K63TefUdiJfKIT_OCD85MryKMvCBLjcM13WYpbxM5aHfGX3CE_0GRhFzQNxV3ymA (last access: 8 February 2022), 2014.
Sun, L. M. and Jin, X. J.: A new method of determining single attribute importance based on Rough Set, Journal of Guangdong University of Petrochemical Technology, 23, 57–59, 2013.
Taheri, R., Ghahramani, M., Javidan, R., Shojafar, M., Pooranian, Z., and Conti, M.: Similarity-based android malware detection using Hamming distance of static binary features, Future Gener. Comp. Sy., 105, 230–247, https://doi.org/10.1016/j.future.2019.11.034, 2020.
Tan, Y. F.: Research on method of attribute weight based on rough sets theory, MS thesis, Guangxi Normal University, China, 50 pp., https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CMFD&dbname=CMFD2012&filename=1012378048.nh&uniplatform=NZKPT&v=mwEoy–uyYZybMi1wb9oRCEtcIVaNQt-8alvWrx3Hwbib11virACW73KANpuo9cd (last access: 8 February 2022), 2012.
Wang, P. J.: Research on key technologies in modular configuration design of machine tool product for mass customization, PhD thesis, Northeastern University, China, 163 pp., https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CDFD&dbname=CDFDLAST2019&filename=1019030975.nh&uniplatform=NZKPT&v=nXArlgytpL9qErVpIsxYZVc1r8UpFihNTiQLg7qLsTjAsHh_sJVyBmC7WGCiTlP0 (last access: 8 February 2022), 2016.
Wei, L. J. and Ma, H. L.: Similarity of soil factors in turfgrass introduction based on the fuzzy similarity priority ratio method, Journal of Gansu Agricultural University, 52, 145–148, 2017.
Wu, J., Liang, C. Y., and Li, W. N.: Method to determine attribute weights based on subjective and objective integrated, Systems Engineering and Electronics, 3, 383–387, 2007.
Xu, J. H., Zhang, S. Y., and Li, Y.: Modular configuration design method for numerical control machine tools based on multi-domain mutual-use, Journal of Mechanical Engineering, 47, 127–134, https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFD2011&filename=JXXB201117021&uniplatform=NZKPT&v=jLYKvjCz7LzlgS3Yv5GnifdRfgzYBYH93LIVwAk4HwBVoL1-KmGjyb3e7vVct8io (last access: 8 February 2022), 2011.
Yuan, Y. Y.: Research on optimization of personalized product configuration driven by customer requirement, MS thesis, Southwest Jiaotong University, China, 78 pp., https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CMFD&dbname=CMFD202102&filename=1021574733.nh&uniplatform=NZKPT&v=i560jJ8W5qGC2V8NfxB_Glai5aG-bHkFkfjAckmOMiyhz8aXIWH3n1yv88Y8jIrf (last access: 8 February 2022), 2020.
Zhang, C. B.: Research on modular design method for CNC machine tools, MS thesis, Northeastern University, China, 79 pp., https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CMFD&dbname=CMFD201402&filename=1014180391.nh&uniplatform=NZKPT&v=33R6wc1US5P2fPQoIfaG4zbDzHRZYm73iQSQJEz7C-TCi_U_WtO2x2uOk5DzXesk (last access: 8 February 2022), 2012.
Zhao, F., Hou, L., Duan, Y., Chen, Z. M., Chen, Y., and Sun, Z. J.: Research on the forming theory analysis and digital model of circular arc gar shaped by rotary cutter, Journal of Sichuan University (Engineering Science Edition), 48, 119–125, https://doi.org/10.15961/j.jsuese.2016.06.017, 2016.
Zhu, H. Y.: Algorithm design of determining weights based on rough set theory, Journal of Huaihai Institute of Technology (Natural Science Edition), 27, 6–9, 2018.
- Abstract
- Introduction
- Determining of the index weight based on rough set theory
- Module retrieval based on the fuzzy similarity priority ratio method
- Design of the machine tool module configuration sequence based on the depth-first search algorithm
- Modular configuration design of the special machine tool for VH-CATT cylindrical gears
- Conclusions
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Determining of the index weight based on rough set theory
- Module retrieval based on the fuzzy similarity priority ratio method
- Design of the machine tool module configuration sequence based on the depth-first search algorithm
- Modular configuration design of the special machine tool for VH-CATT cylindrical gears
- Conclusions
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References